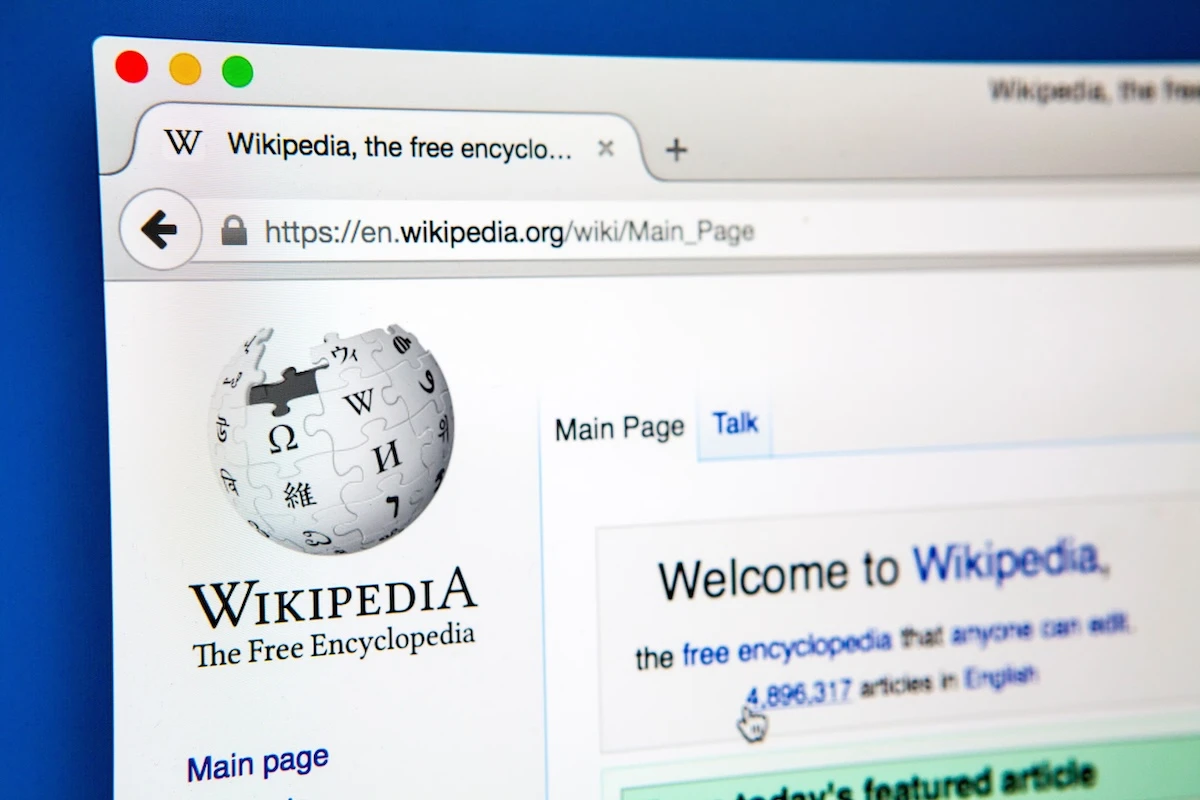
Википедия просит ИИ-ботов не нагружать серверы энциклопедии
Руководство Wikimedia предпринимает шаги, чтобы отговорить разработчиков ИИ от безудержного сбора данных с Википедии. Для этого компания предлагает им более удобную альтернативу — специально подготовленный датасет, оптимизированный для обучения моделей искусственного интеллекта. Об этом в среду объявил представитель компании, сообщив, что начал сотрудничество с Kaggle — платформой для сообщества специалистов по данным, которая принадлежит Google. Теперь на Kaggle доступна бета-версия набора данных, который содержит структурированный контент Википедии на английском и французском языках. По словам представителей Wikimedia, этот датасет создан с учйтом потребностей в машинном обучении — он предоставляет легко читаемую машиной информацию, подходящую для настройки моделей, проведения анализа, тестирования, выравнивания и других задач.
Google внедрила ИИ в поиск YouTube…
Сегодня компания Google начала тестировать новый формат поиска для YouTube, который напоминает AI Mode в …
Сегодня компания Google начала тестировать новый формат поиска для YouTube, который напоминает AI Mode в …
Google позволит удалить личные данные из сети…
Google расширяет набор инструментов для удаления конфиденциальной информации и изображений, опубликованны…
Google расширяет набор инструментов для удаления конфиденциальной информации и изображений, опубликованны…
В Google Gemini появился импорт и экспорт истории ИИ…
После того как компания Anthropic обновила свой инструмент для переноса памяти между чат-ботами в систему…
После того как компания Anthropic обновила свой инструмент для переноса памяти между чат-ботами в систему…
Браузер Opera GX выпустили на Linux…
Игровой браузер Opera GX от норвежской компании Opera наконец стал доступен на платформе Linux. Теперь по…
Игровой браузер Opera GX от норвежской компании Opera наконец стал доступен на платформе Linux. Теперь по…
Генератор видео Sora добавят в ChatGPT…
Генератор видео Sora от OpenAI в ближайшее время может стать встроенной функцией ChatGPT. Сейчас Sora дос…
Генератор видео Sora от OpenAI в ближайшее время может стать встроенной функцией ChatGPT. Сейчас Sora дос…
Samsung выпустила ИИ-браузер для десктопа…
Сегодня компания Samsung представила нового ИИ-ассистента для браузера Samsung Browser, созданного в парт…
Сегодня компания Samsung представила нового ИИ-ассистента для браузера Samsung Browser, созданного в парт…